shardingjdbc
官方文档:
https://shardingsphere.apache.org/document/5.1.1/cn/user-manual/
MySQL 不支持的 SQL 清单
https://shardingsphere.apache.org/document/5.1.1/cn/features/db-compatibility/sql-parser/mysql/
整理文档:
https://lvxueyang.vip/post/718ce14b.html
https://juejin.cn/post/7022437322474029064
简介
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的基于数据库作为存储节点的增量功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
数据分片
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
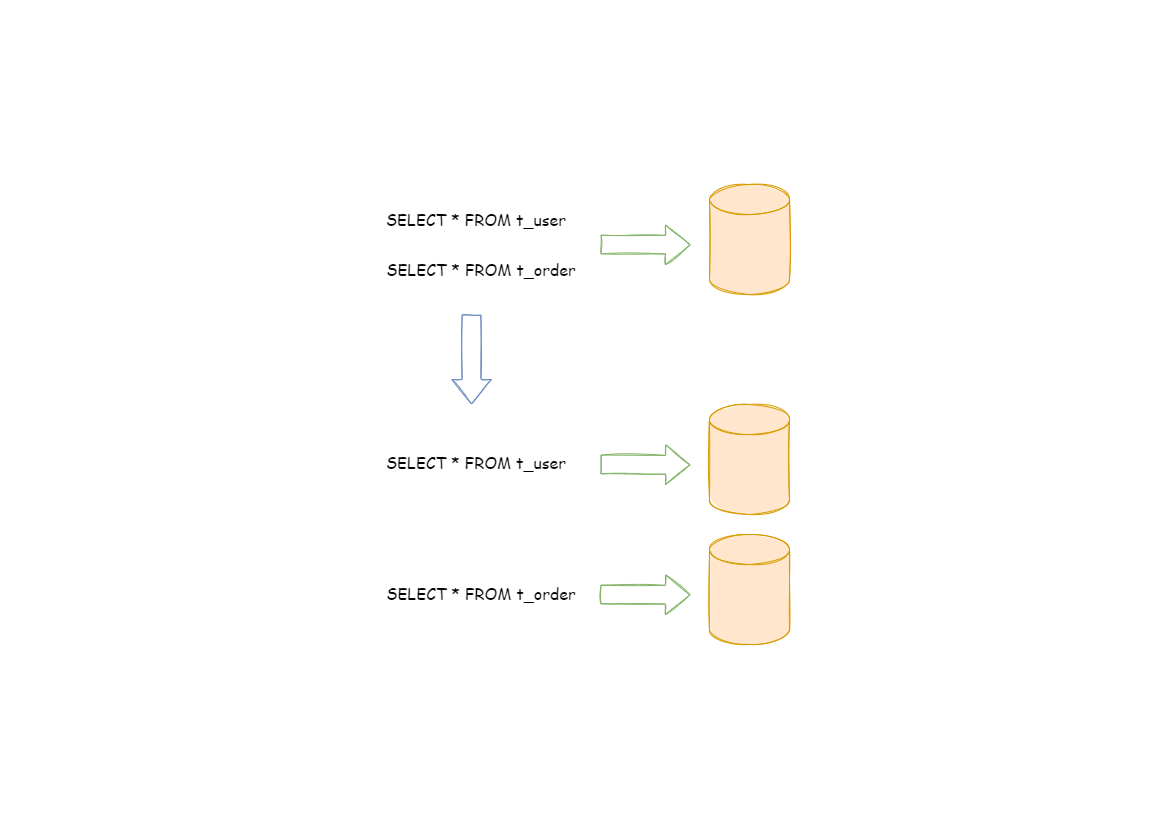
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
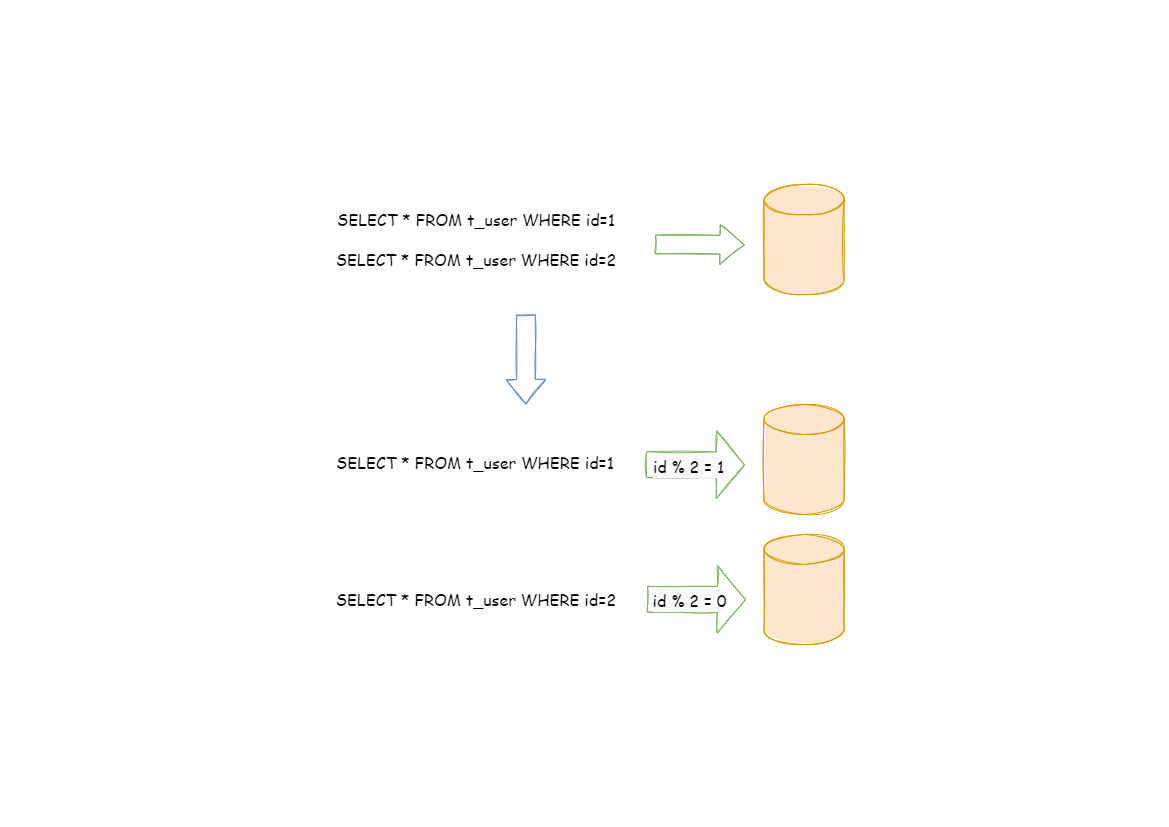
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
读写分离
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
与将数据根据分片键打散至各个数据节点的水平分片不同,读写分离则是根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库。
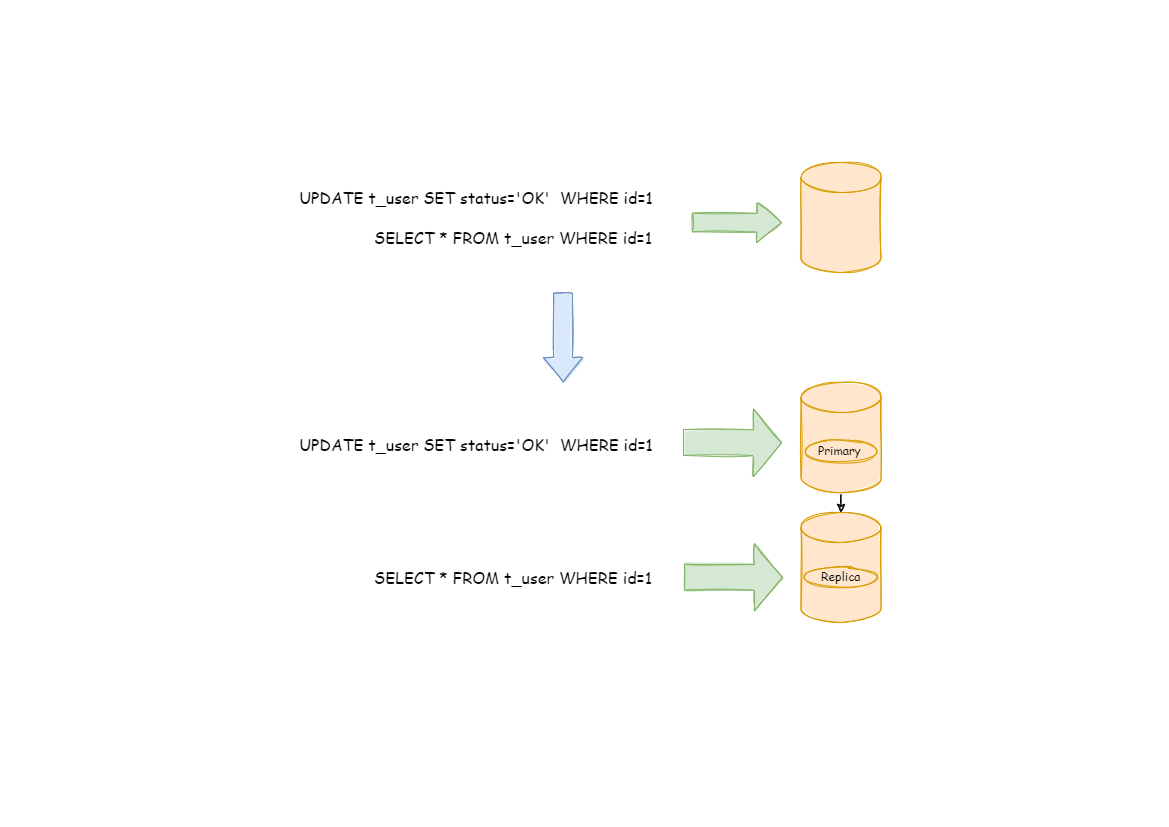
读写分离的数据节点中的数据内容是一致的,而水平分片的每个数据节点的数据内容却并不相同。将水平分片和读写分离联合使用,能够更加有效的提升系统性能。
核心概念
主库
添加、更新以及删除数据操作所使用的数据库,目前仅支持单主库。
从库
查询数据操作所使用的数据库,可支持多从库。
主从同步
将主库的数据异步的同步到从库的操作。 由于主从同步的异步性,从库与主库的数据会短时间内不一致。基于mysql的binglog日志
负载均衡策略
通过负载均衡策略将查询请求疏导至不同从库。
分布式事务
背景
数据库事务需要满足 ACID(原子性、一致性、隔离性、持久性)四个特性。
- 原子性(Atomicity)指事务作为整体来执行,要么全部执行,要么全不执行;
- 一致性(Consistency)指事务应确保数据从一个一致的状态转变为另一个一致的状态;
- 隔离性(Isolation)指多个事务并发执行时,一个事务的执行不应影响其他事务的执行;
- 持久性(Durability)指已提交的事务修改数据会被持久保存。
在单一数据节点中,事务仅限于对单一数据库资源的访问控制,称之为本地事务。 几乎所有的成熟的关系型数据库都提供了对本地事务的原生支持。 但是在基于微服务的分布式应用环境下,越来越多的应用场景要求对多个服务的访问及其相对应的多个数据库资源能纳入到同一个事务当中,分布式事务应运而生。
关系型数据库虽然对本地事务提供了完美的 ACID 原生支持。 但在分布式的场景下,它却成为系统性能的桎梏。 如何让数据库在分布式场景下满足 ACID 的特性或找寻相应的替代方案,是分布式事务的重点工作。
本地事务
在不开启任何分布式事务管理器的前提下,让每个数据节点各自管理自己的事务。 它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。 本地事务在性能方面无任何损耗,但在强一致性以及最终一致性方面则力不从心。
支持项
- 完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中;
- 完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能够回滚。
不支持项
- 不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交,且无法回滚。
两阶段提交
XA 协议最早的分布式事务模型是由 X/Open 国际联盟提出的 X/Open Distributed Transaction Processing (DTP) 模型,简称 XA 协议。
基于 XA 协议实现的分布式事务对业务侵入很小。 它最大的优势就是对使用方透明,用户可以像使用本地事务一样使用基于XA协议的分布式事务。 XA协议能够严格保障事务 ACID 特性。
严格保障事务 ACID 特性是一把双刃剑。 事务执行在过程中需要将所需资源全部锁定,它更加适用于执行时间确定的短事务。 对于长事务来说,整个事务进行期间对数据的独占,将导致对热点数据依赖的业务系统并发性能衰退明显。 因此,在高并发的性能至上场景中,基于 XA 协议的分布式事务并不是最佳选择。
支持项
- 支持数据分片后的跨库事务;
- 两阶段提交保证操作的原子性和数据的强一致性;
- 服务宕机重启后,提交/回滚中的事务可自动恢复;
- 支持同时使用 XA 和非 XA 的连接池。
不支持项
- 服务宕机后,在其它机器上恢复提交/回滚中的数据。
- Savepoint。
- 事务块内,SQL 执行出现异常,执行 Commit,数据保持一致。
柔性事务
如果将实现了 ACID 的事务要素的事务称为刚性事务的话,那么基于 BASE 事务要素的事务则称为柔性事务。 BASE 是基本可用、柔性状态和最终一致性这三个要素的缩写。
- 基本可用(Basically Available)保证分布式事务参与方不一定同时在线;
- 柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉;
- 最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
在 ACID 事务中对隔离性的要求很高,在事务执行过程中,必须将所有的资源锁定。 柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。 通过放宽对强一致性要求,来换取系统吞吐量的提升。
基于 ACID 的强一致性事务和基于 BASE 的最终一致性事务都不是银弹,只有在最适合的场景中才能发挥它们的最大长处。 可通过下表详细对比它们之间的区别,以帮助开发者进行技术选型。
| 本地事务 | 两(三)阶段事务 | 柔性事务 | |
|---|---|---|---|
| 业务改造 | 无 | 无 | 实现相关接口 |
| 一致性 | 不支持 | 支持 | 最终一致 |
| 隔离性 | 不支持 | 支持 | 业务方保证 |
| 并发性能 | 无影响 | 严重衰退 | 略微衰退 |
| 适合场景 | 业务方处理不一致 | 短事务 & 低并发 | 长事务 & 高并发 |
支持项
- 支持数据分片后的跨库事务;
- 支持 RC 隔离级别;
- 通过 undo 快照进行事务回滚;
- 支持服务宕机后的,自动恢复提交中的事务。
不支持项
- 不支持除 RC 之外的隔离级别。
使用发现的问题:
包装了一层函数后不会走自定义分片规则
AND DATE_FORMAT(his.HAPPEN_TIME,'%Y-%m-%d %H:%i:%S') BETWEEN DATE_FORMAT(#{eventSignalHis.beginTime} ,'%Y-%m-%d %H:%i:%S') AND DATE_FORMAT(#{eventSignalHis.endTime} ,'%Y-%m-%d %H:%i:%S')AND his.HAPPEN_TIME BETWEEN #{eventSignalHis.beginTime} AND #{eventSignalHis.endTime}如果是用了上班的方式包装了一层函数,就不会走自定义的分片逻辑